
http://livingriver.eu/?page_id=936 One of the difficulties in creating a transcript and analyzing textual patterns in the Voynich Manuscript is the ambiguity in some of the characters. When this occurs in common words, it makes it more difficult to assess glyph relationships and frequencies.
Bangkok A simple example might illustrate this problem. I mentioned in my previous blog that I believe the paired c-shapes are meant to be read as one character (in most instances). There is also a single c (EVA-e) which may occur next to a double-c, to create three in a row. When there are three in a row, how does one decide whether it’s three cees, a double-c following to a single-c, or a single-c following a double-c?

In this example, I’m leaning toward the VMS glyphs (top) being two double-c shapes because of the slightly larger gap between the two pairs and the way the cc behaves in other parts of the manuscript, but I’m not 100% sure because the two latter cees are more tightly written than the first two. Is this normal pen-variation or are the first two cees single cees followed by a double-c?
Sometimes all we have to go on is slight differences in the spaces between characters and that’s not a good way to do it—there will always be some uncertainty, which is one of the reasons I feel it’s important to study the rule set and possible pairing paradigm for the VMS. Then the context can help us determine which glyphs are intended as ligatures and which might function as pairs.
The Devil in the Details
Unfortunately, ambiguity exists in one of the most common VMS word-tokens, one that is popularly called “dain”. I don’t use the EVA font-set, I developed my own based on shape designations, but you should be able to see the correspondence in the following illustration fairly readily.
In this example, there is ambiguity in the straight shape that alternately resembles a double-i or possibly a “u” as it was often written slightly separated, with straight legs, in the middle ages. I use a “v” and sometimes a “w” to describe the ending shape with a tail but I make no assumptions about what these shapes mean or whether the swept-up tail indicates an abbreviation, as it would in classical Latin, or whether it is an embellished glyph designed to look like Latin, just as the “9” shape (EVA-y) morphologically and positionally follows Latin conventions:
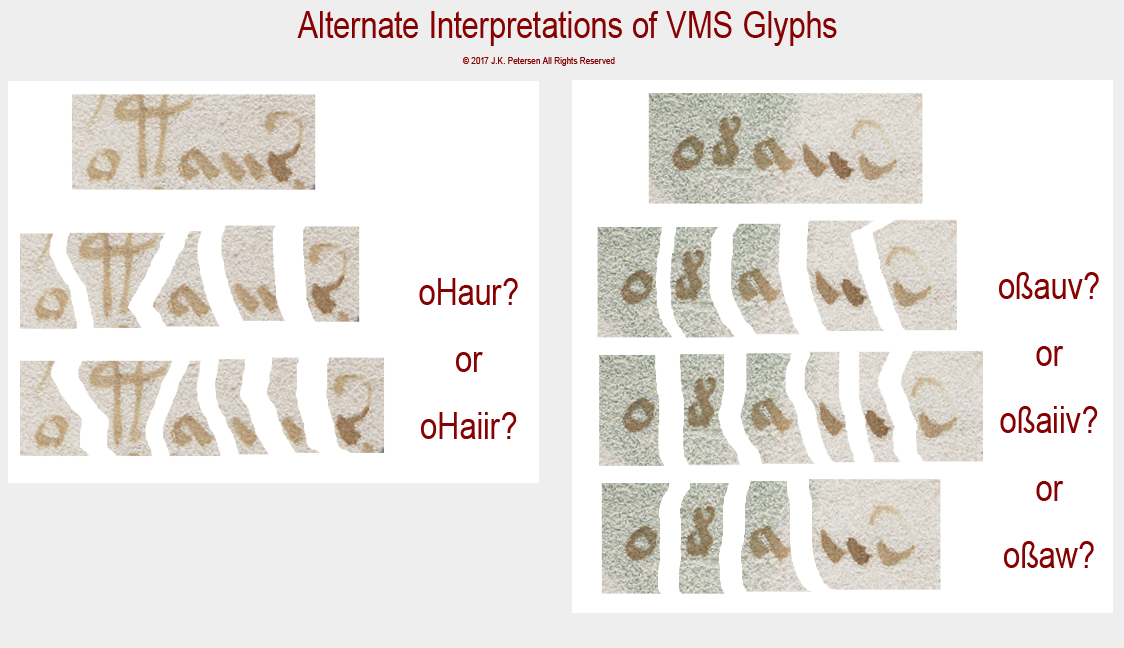
To complicate matters further, there are places in the manuscript where there is an additional stroke between the a-shape and the swept-up tail, one that Takahashi (and perhaps other transcribers) sometimes missed.
Summary
A fresh transcript is needed, and not just a “corrected” transcript that makes better assessments of the spaces (I’ve noticed errors in which glyphs with clear spaces around them have been attached to nearby words), but one in which all the glyphs are included, even ones that “look funny” because there are so many in a row, along with consideration for alternate interpretations for ligatures (combined glyphs) and paired glyphs.
I created a transcript that corrects some of these problems, but it’s not a stand-alone file. I’ve integrated it with a set of self-made VMS fonts and applications so that the whole thing is an interdependent set of tools that can’t really be split apart as they currently stand.
I can make some suggestions, however. When I created my fonts, I put the VMS characters in the upper register and the regular characters in the lower register as they are usually typed on the keyboard, so that it’s seamless to combine VMS and regular characters in the same document (handy if you’re writing an article about the VMS). This also allows comments to be added to the transcript that don’t interfere with searches of the VMS glyphs. Unicode standards have plenty of space for this, and it’s not difficult to come up with mnemonic references to the shapes to make it easier to type. I also set up glyphs that are similar such that they can be searched together or separately. Adding a symbol to the glyph is usually a better overall solution than putting each variation of a basic form in a different font-slot, a point that I’ll discuss more fully in my next blog.
J.K. Petersen
© Copyright 2017 J.K. Petersen, All Rights Reserved
I think that the most difficult part is to eliminate the interpretation (‘what could it mean’) from the transcription.
It is good (and probably necessary) to record whether two c-shapes do or do not touch each other.
The interpretation (i.e. the next step) could then try the various options
JK
This looks great. To have a font that moves easily between plain and Voynichese script is just what is needed. Brilliant.
I’ve been curious about the carolingian open a in the VMs for a while because as a positional variant, it could correspond to a morpheme in french and german: An “open front unrounded vowel”, like in german “Kamm [kʰam]” or french “avoir [aˈvwa:ʁ]”, in contrast to french “âme [ɑm]”, an “open back unrounded vowel”. It is a very subtle distinction, which could to have lost importance over the centuries.
There are different types of transcriptions. An “allographetic” or “palaeographic” transcription[1] would simply record what is seen (according to a previously metricised script model). An ambiguity is an “allograph(y)”, would be noted, classified.. same for ligatures etc., from then on it’s 2nd order statistics. That’s at the very heart of the palaeographic method. By now there is softwares to help with these daunting tasks (recording positions is essential for text-to-image-linking).
It is sometime really hard to keep track of all the “wheel re-inventions” in VMs research.
1: https://www.balisage.net/Proceedings/vol16/print/Lavrentiev01/BalisageVol16-Lavrentiev01.html#palaeographic
.. re spacing (phonotactics): look at how many spaces are required by medievalists to transcribe:
http://skaldic.abdn.ac.uk/db.php?char=-+formatting&if=mufi&table=mufi_char
By “upper register”, are you referring to Unicodes’s PUA (Private Use Area)?
It definitly pays to take a look at MUFI, the Medieval Unicode Font Initiative and their code charts.
http://folk.uib.no/hnooh/mufi/
Why is the VMs alphabet not included in Unicode? Because nobody ever proposed it!
“(…) There are currently no plans to encode the Voynich alphabet in Unicode. It is not on the roadmap, and no-one has submitted an encoding proposal for it — and apart from a couple of disparaging remarks in 1999 and 2005 it has not even been discussed on the Unicode mailing list. With our current lack of understanding of the Voynich alphabet it is unlikely that it would be accepted for encoding by the committees, but if it could be proved (and that proof widely accepted) that Voynich does represent natural language and is not a cipher for an existing script, then I think it would be a good candidate for encoding. On the other hand, encoding policy has become noticeably more liberal in recent years, and it is always possible that a well-written proposal with compelling justification for why a character encoding of Voynich is required by scholars might eventually be successful. But unless someone puts the effort into writing and championing such a proposal we will never know.”
(http://babelstone.blogspot.de/2013/10/whats-new-in-unicode-70.html)
Since my font and transcription were created for my own use about seven years ago, I was free to use any of the higher registers that were available (including the PUA). I have three different renditions of the VMS fonts and one is situated in a “slot” that already had many shapes similar to the VMS glyph shapes around the Hex 0235 028D area. I chose it for convenience, and because some of the shapes were already mnemonically familiar (for ease of typing). None of this is set in stone—it’s relatively easy to move them elsewhere and I am always fine-tuning the fonts and my ideas on how they could be implemented.
I found your information about the reaction of the Unicode community quite interesting. Since I can see that they might want to reserve limited space for natural language alphabets, I suppose there are practical reasons for not including VMS fonts, but I see no reason why Voynich researchers couldn’t come up with some practical ways in which Voynichese could best be implemented and perhaps, in the future, depending on what happens, it would provide a head start on making the fonts more broadly available.
Maybe it’s a good thing it’s not yet Unicode standard. If the fonts get “locked down” and we then uncover aspects of the text that change our ideas of what the glyphs mean, the schema could be updated to reflect this.
Hi JKP, that Carolingian script with the strange ‘a’ is very interesting! Do you please have a link to images of whole pages?
Sorry I did not see your request sooner, Marco, I’ve been pretty busy and neglected to check the blog for comments.
Here is a link to Oribasius (pre-Carolingian) on Gallica. It has a great variety of “a” shapes, including both single- and double-story “a” and the open double-cee-shaped “a”. You’ll note that when they are written as ligatures that both the “g” and “e” shapes also sometimes resemble a cee-shape:
http://gallica.bnf.fr/ark:/12148/btv1b60004321/f598.item.zoom
Here’s another example in which the two cee shapes are more tightly coupled, so that the “a” almost looks like a fish:
http://www.mmdc.nl/static/media/1/88/KB%2073%20B%2024%20-%20fol%2013%20-%20detail%20S.JPG
By Carolingian times, the double-cee-shaped “a” was starting to die out, replaced by the single- and double-story “a”, but one can still find occasional examples. The VMS glyph shapes are somewhat reminiscent of these older documents.
I sometimes wonder if the VMS was copied from older documents that the scribe couldn’t quite read and thus interpreted dissimilar shapes as the same glyph but… the structure in the VMS tokens argues against this. Assuming the spaces are to be interpreted literally, it’s too regimented to be natural language, even if one allows for the possibility of copying/interpretation errors.
Thank you, JKP!
These manuscripts look quite interesting (and difficult to read). I am looking forward to spend some time trying to get a grasp on these scripts 🙂
Hi my name is Darren. I am interested in your typeface. I have tried to use Voynich 123 in Photoshop and Illustrator and find them incomplete. I am trying to rebuild f57v in Illustrator, but don’t want to get into Font Studio Pro and make my own typeface unless necessary.
Do you feel comfortable with Photoshop? I’ll send you a file and show you something that you might find interesting…
Your blog makes a number of amazing points, particularly regarding the Latin and f57v.
What if VMS was written by a woman?
Hello, Darren, I cannot release my VMS fonts at the present time because they are integrated with the apps I use with my transcription. At some point in the future I might choose to do it, but I am still working on refinements to increase their utility.
Yes, I’m completely comfortable with Photoshop and other graphics tools.
I’ve always considered the possibility that the VMS was written by a woman. Many traditional themes in the manuscript that are usually drawn with male figures are illustrated instead with female nymphs, except when sexual context is specifically expressed (as in one of the zodiacs and one of the pool pages). In fact, there is a historical precedent for women inventing their own scripts in China, where the women did not go to school but passed down a phonetic script of their own design (called Nüshu) through their female contacts.
It’s also possible it was a man used to being around women (Lewis Carroll, for example, had seven sisters, and men who guard harems were constantly around women). I even looked up the history of eunuchs, to see whether the practice was still prevalent in the 15th century (it had mostly disappeared by then). And then there are always gender-ambiguous and cross-gender individuals whose sexual orientation is outside the majority who might approach a manuscript like this from a unique point of view. Or, it could be a man interested specifically in women’s health (the medieval equivalent of a modern ob/gyn), or possibly a manuscript that was commissioned by a female patron and tailored to her wishes.
There is no way to be sure, so I usually refer to the scribes/illustrator in the neutral so as not to imply he/she or they were either male or female.