
16 May 2019
A week ago I posted commentary on Gerard Cheshire’s “proto-Italic ” and “proto-Romance” solution for the VMS. At the time, his most recent paper was pay-to-view, so I had to restrict my comments to the previous open-access paper. Now the most recent version is open-access. Unfortunately, not much has changed from the previous version. You can see his April 2019 proto-Romance theory here.
What exactly do the terms “proto-Romance” and “proto-Italic” mean?
Proto-Romance
If you search for “proto-Romance”, you will find many references to “vulgar Latin” (also called colloquial Latin)—variations of Latin spoken by the common people (most of whom were illiterate) during the classical period of the Roman Empire.
The “classical period” of the Greeks and Romans spanned approximately 14 centuries up to about 6th century C.E. when the Roman Empire was no longer dominant. As Rome lost its grip, vernacular languages and local versions of Latin had the opportunity to evolve into modern languages such as Italian/Sardinian, Spanish, Portuguese, French (with Gaulish influence), and Romanian.
Extinct Languages and Undocumented Scripts
The prefix “proto-” comes from Greek πρωτο-. This refers to the first, or to something that comes before. So proto-Romance means before the Romance languages had fully emerged (from vulgar Latin), and proto-Italian script means an alphabet that was used before the script that became standard for writing medieval Italian. Medieval Italian script is essentially the same alphabet we use now except that the letterforms are more calligraphic than modern computer users are accustomed to seeing.
This brings us back to Cheshire, who is claiming that Voynichese is an extinct proto-Romance language in an undocumented proto-Italian script… something that existed about 1,000 years before the creation of the VMS.
How is that possible when the radiocarbon-dating and many of the iconographical and palaeological features of the VMS point to the early 15th century?
Cheshire’s Interpretation of Medieval Characters
Cheshire’s descriptions of individual glyphs, and his interpretations of the annotations on folio 116v, suggest that he is not familiar with medieval scripts.
It also seems that he hasn’t studied the frequency or distribution of the Voynich glyphs in the larger body of the main text, because he associates common letters and letter combinations with glyphs that are rare, or that have unusual positional characteristics. This point is so important, it bears repeating… Cheshire assigned substitution values for common letters to rare VMS glyphs, or glyphs that have positional characteristics that are not consistent with Romance languages.
Is it possible he never tested his system to see if it would generalize to larger chunks of text? Did he prematurely assume he had solved it?
Let’s look at some examples…
Cheshire’s Analysis and Transliteration of Voynich Glyphs
In his first example, Cheshire takes a glyph-shape that is known to palaeographers as the Latin “-cis” abbreviation (the letter c plus a loop that usually represents “is” and its homonyms). This shape is both a ligature and an abbreviation in languages that use Latin scribal conventions. It has not yet been determined what it means in the VMS, but its positional characteristics are similar to texts that use the Latin alphabet.
VMS researchers know this shape as EVA-g.
Cheshire transliterates it as a “ta” diphthong. It’s not a diphthong. A diphthong is a combination of two vowel sounds and “t” is clearly not a vowel. The terminology is wrong.
He then gives an explanation of the shape that doesn’t mesh with medieval interpretations of letter shapes. This is figure 26 from his paper (Source: tandfonline):

To say that this can be confused with the letter r and the letter n makes no sense to anyone accustomed to reading medieval manuscripts. It looks nothing like r or n. If Cheshire means it can be confused with his transliterated r or n, he should clarify and provide examples.
To get a sense of how this character was used in the medieval period, I have created a chart with examples of the “-cis” ligature/abbreviation that was common to languages that used Latin scribal conventions. I have sorted them by date.
This is not to imply that the Latin meaning and the VMS meaning are the same. The VMS designer may only have borrowed the shape, but it is important to note that the position of this glyph in the VMS is very similar to how it is positioned in Latin languages:
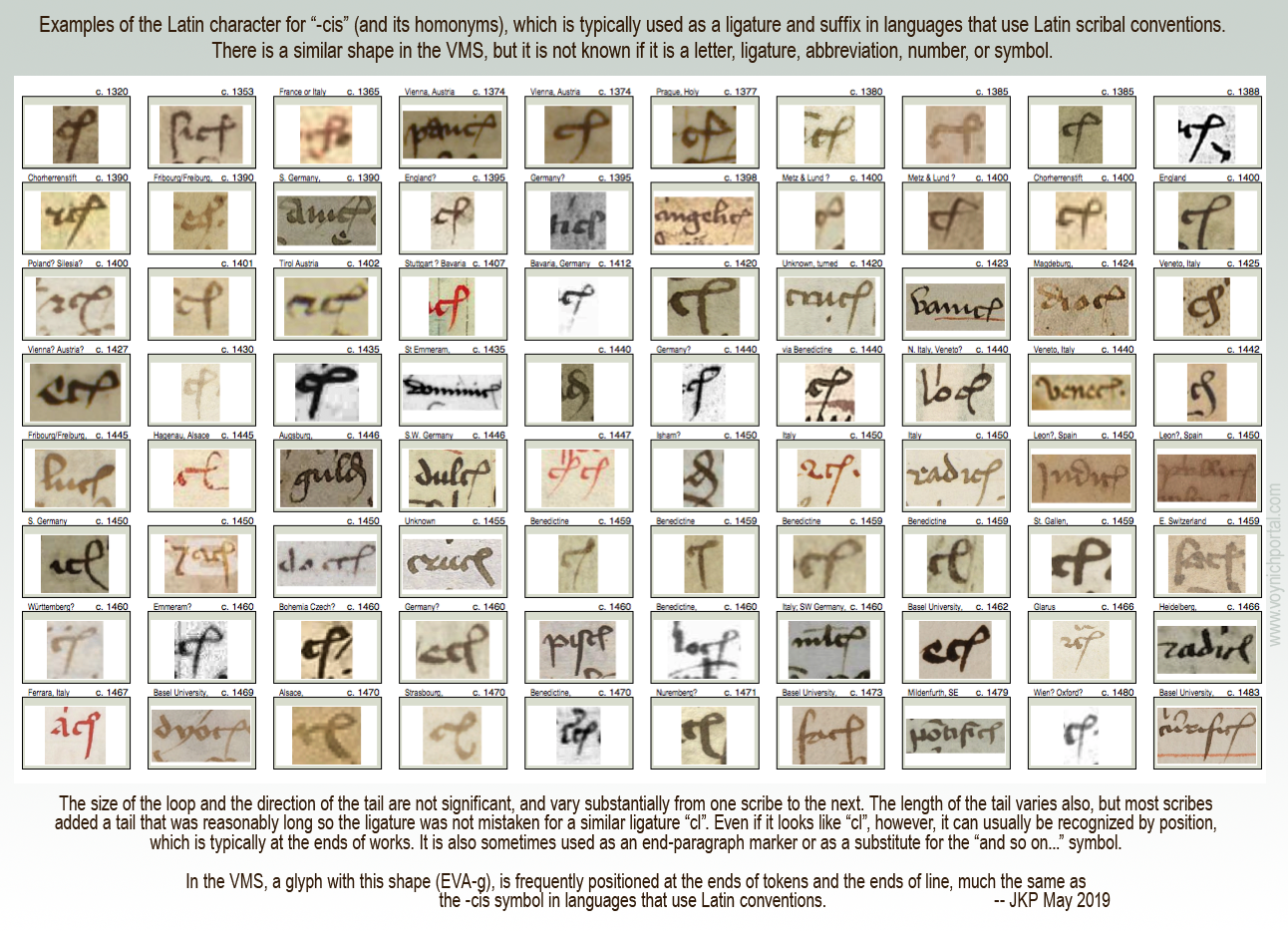
More important than the mistakes in reading medieval characters and linguistic terminology is that Cheshire did not address the basic statistics of VMS text and the fact that this glyph occurs primarily at the ends of words and sometimes the ends of lines. Thus, transliterating EVA-g as “ta” is highly questionable.
Perhaps Cheshire can justify this mismatch between letter frequency and position by saying that separate glyphs also exist for “t” and “a”, but when you put the various transliterations together, one finds that the character distribution of Romance-language glyphs and Cheshire transliterations are significantly out-of-synch.
For example, as in his previous paper, he chose one of the rarest glyphs in the VMS repertoire (EVA-x) to represent the letter “v”. In classical Latin and Romance languages, the letters “u” and “v” are essentially synonymous and very frequent. In this brief excerpt in modern characters, from Pliny the Younger, note how often u/v occurs:


If Voynichese were a proto-Romance language (some form of classical vulgar Latin), and EVA-x were transliterated to U/V and also F/PH, as per Cheshire’s system, one would expect to see this character more than 40,000 times in 200+ pages. Instead, this character occurs less than 50 times. That alone should create doubt in people’s minds about Cheshire’s “solution”.
So what has Cheshire done? He has assigned a different letter to represent “u”, but we know that in classical Latin, Etruscan, and Old Italic, “v” and “u” did not represent different letters even if both shapes were used (which they usually weren’t).
Even in the Middle Ages, when there were different shapes for “u” and “v”, most scribes used them interchangeably. In other words, “verba” might be written with the “v” shape in one phrase and with a “u” shape (uerba) in the next, just as “s” was written with several different shapes (without indicating any difference in sound).
This is the 23-character Latin alphabet in use around the time vulgar Latin was evolving into Romance languages:

Perhaps Cheshire didn’t know that they were interchangeable shapes rather than two different letters when he created his transcription system. But if he did know, if he actually believes that “u” and “v” were distinct letters in proto-Romance languages, he will have to provide evidence, because historians, palaeographers, and linguists are going to be skeptical.
Beginning-Paragraph Glyphs
Voynich scholars have noticed there are disproportionate numbers of EVA-p/r and EVA-t/k characters at the beginnings of paragraphs. There is a possibility that some are pilcrows, or serve some other special function when found in this position.
Cheshire doesn’t appear to have noticed this unusual distribution (at least he doesn’t comment on this important dynamic in his paper) and translates the leading glyph in the same ways as the others. In his system, a very large number of paragraphs inexplicably begin with the letter “P”.
Some of his translations cannot be verified. For example, he used a drawing on f75r to demonstrate a single transliterated word “palina” on f79v. There’s no apparent relationship between them (other than what he contends), so how does an independent party determine if the translation is correct?
Tenuous Assertions
On f70r, he uses a circular argument to explain the transliteration of “opat” (which he says is “abbot”). He says the use of “opat” indicates “that proto-Romance reached as far as eastern Europe” because “opát survives to mean abbot in Polish, Czech and Slovak”.
We don’t need a dubious transliteration to tell us that proto-Romance languages reached eastern Europe. The existence of Romania demonstrates this rather well—it borders the Ukraine, and used to encompass parts of Bohemia. Bohemia included Hungary, Czech, and parts of eastern Germany, so transmission of vulgar Latin to Polish through Czech was a natural process.
Palaeographical Interpretations
There are problems with the way Cheshire describes the text on folio 116v. He refers to the script as “conventional Italics”. It is, in fact, a fairly conventional Gothic script, not “conventional Italics”.
Then he makes a strange statement that the second line on 116v is hybrid writing, that it is Voynichese symbols mixed with “prototype Italic symbols, as if the calligrapher had been experimenting with a crossover writing system”. It’s hard to respond to that because his statement is based on misreading the letters. Here is the text he referenced in his paper:

Cheshire interprets this as “mériton o’pasaban + mapeós”
He misread a normal Gothic h as the letter “r” and a normal Gothic “l” as the letter “P”. In Gothic scripts, the figure-8 character is variously used to represent “s”, “d”, and the number 8, so it’s very familiar to medieval eyes, but he doesn’t seem to know that and interpreted it as a Voynich character that he transliterated to “n”.
If his reading of the letters is wrong, then his transliteration is going to be wrong, as well.
Zodiac Gemini Figures
Cheshire mentions the Gemini zodiac figures (the male/female pair), and states: “Both figures are wearing typical aristocratic attire from the mid 15th century Mediterranean.”
It takes research to determine the location and time period for specific clothing styles—it’s not something people just automatically know. Since Cheshire didn’t credit a source for this reference, I will. It’s possible he got the information from K. Gheuen’s blog.. Even if he didn’t, Gheuen’s blog is worth reading.
Flora and Fauna
I’m not going to deal with Cheshire’s fish identification. It’s just as dubious as the Janick and Tucker alligator gar. There are fish that are more similar to the VMS Pisces than Cheshire’s sea bass, and pointing out the fact that sea bass has “scales” is like pointing out that a bird has wings.
I was hopeful that Cheshire’s latest paper would be an improvement over his previous efforts, but I was disappointed.
Summary
It’s possible there is a Romance language buried somewhere in the cryptic VMS text (it was, after all, discovered in Italy, and the binding is probably Italian), but that is not what Cheshire is suggesting. He’s saying it’s an extinct proto-Romance language, without providing a credible explanation of how this information could have been transmitted a thousand years into the future.
There is a relentless publicity campaign going on right now to catapult Cheshire into the limelight. I’m not going to repeat the claims in the news release (they’re pretty outrageous), but even Superman would blush at the accolades being heaped on this unverified theory.
When I checked Cheshire’s doctoral research, I discovered it was in belief systems. Somehow that seems fitting.
J.K. Petersen
© Copyright 2019 J.K. Petersen, All Rights Reserved
Postscript 16 May 2019: The University of Bristol has retracted the Cheshire news release. You can see the retraction here for as long as they decide to make it available.
Thanks for this JKP – it’s always great to have a linguistic evaluation of claimed translations.
The preservation of a text for 1,000 years is not remarkable in itself. After all we still have Latin works written in the 1stC AD, and Augustine (who wrote in the 4thC) – not to mention Pliny, Julius Caesar, Herodotus, Homer and.. of course.. the Bible.
But in all those cases, we know the languages themselves were in continuing use – so someone in the fifteenth century could still read them.
I’m not sure that Cheshire is saying a text was preserved for 1,000 years—he isn’t very explicit on this point. But the way the paper is written implies that someone in the 15th century was able to write in a language that was 1,000 years old that had become extinct, using an “undocumented” script. If this supposed language that existed in classical times was extinct AND the script undocumented, how could someone in the Middle Ages have discovered and reproduced it?
I suppose it’s unwise to look for a coherent theory in this mess, but in a previous article Cheshire was explicit about when the language of the manuscript evolved:
“The version of proto-Romance language used in Manuscript MS408 is closest linguistically to Portuguese, Catalan, Galician and Occitan. This is evidently due to the language having developed from Vulgar Latin at a time when Naples, Ischia and the Aeolian Islands were part of the Crown of Aragon.” (p. 36)
https://www.academia.edu/35769087/Linguistically_Dating_and_Locating_the_Origin_of_Manuscript_MS408_Ischia_1444
Per Wikipedia, Ischia belonged to the crown of Aragon for about 16 years in the late 13th century and about 8 years before the suggested date of the manuscript in the 15th century.
So the idea seems to be that the people of Ischia spoke Vulgar Latin until at least the late 13th century, and then their language developed into proto-Romance.
Thank you for your information, Chris.
There isn’t actually a language called “proto-Romance”. It’s a general term for the numerous dialects of vulgar Latin that existed in classical times that developed into Romance languages. I’m not disputing that vulgar Latin survived past the classical period, but vulgar Latin didn’t develop into “proto-Romance”—it was proto-Romance—and from there evolved into Romance languages.
The frequency statistics for the alphabet used in Cheshire’s “translation” are significantly different from any Latin or other Romance language, so this has to be resolved before he can make the leap that the VMS text represents an “extinct” proto-Romance language.
Thanks for this! Very interesting reading and I was very skeptical about this article/theory/translation but I don’t have the bona fides to actually prove it was ^&^( myself.
Please don’t get the idea I’m giving any credence to this. I think it’s ridiculous.
@ Ladies and Gentlemen: Please close down the “Voynich discussions — and focus on the languages which appear in B-408 (Boenicke Library at Yale University).
Fray Sahagun’s parents gave him a ‘going-away’ present of some thirty (or more) parchments — for his use as a student of the University of Salamanca.
Beady-Eyed Wonderer
This is an excellent article. I take issue in a small way with the suggestion in the first section that Romanian and French are languages that evolved directly from Vulgar Latin. Langue d’Oc and Langue d’Oil evolved from Vulgar Latin, certainly, and there were still native speakers of Langue d’Oc in southern France as late as 1850, and the same is true of Provencal, and the whole continuum of Romance languages from Sicilian through Neapolitan to Veneto and Romansh west and south west to Galician. But Romanian? The idea that Romanian is derived from a relict population of Dacian Romans is a modern nationalist theory, and very suspect. There is good reason to believe that Romanian came into the territories of Romania and Moldova from the south-west with the Wlachs no earlier than the 11th century. Dacia was never a proper Romanised province like Britannia, it was just looted for gold for a short period of time, then abandoned. The area was invaded and occupied by hordes of Huns, Goths and the rest for centuries. So Romanian didn’t evolve from the local version of Latin as this article states. This is however a small point. The rest of the article is important, unlike this comment of mine…
Thank you for your comment. I appreciate you filling in some of the gaps for those of us who are not trained linguists but who are interested in learning more about the subject.
Perhaps I’m insane, but if his method actually works to translate larger portions of the text, than what does it matter if it makes sense in the context of what we already know about other ancient languages? I understand, that at this point a larger sampling of text may not have been translated. I just think that if the text was translatable using rules we already know about languages, it would have been done already. So he’s coming at it from an angle you don’t like. It doesn’t align with what you think you know. Neither does the manuscript. Perhaps someone who doesn’t have a background in languages can look at the text without the hinderance of these rules. And it is entirely possible, since he finds that its phonetic, that the author him/herself did not have a strong mastery of the language they were attempting to write. Maybe they were self taught. Maybe they were a bad speller. I’m not saying he has broken the code. I’m simply offering a different perspective. People who know “the rules” have a hard time operating outside of them. This text doesn’t seem to follow the rules though.