
8 9 April 2020
A Web search led me to this University of Florida News article about a “secret code” in a mid-13th-century manuscript:
“ Arusha Medieval book’s secret code remains unbroken
… Somewhere during its journey through medieval Europe, several people wrote notes in the margins of the book. The notes in brown ink are mostly Roman numerals, but the writing in red — which, from the style of the letters, seems to be from the fourteenth century — is mysterious. Some of the scribbles seem to be words, but they’re illegible. Others form a cryptic code of repeating letters….”
Here’s a screensnap that illustrates the notes in red ink. They are on almost every folio in the first half of the book, but become less frequent after page 100:

I scanned through the manuscript from beginning to end looking for ciphertext or anything that might be considered as “secret code”. I couldn’t find any. I agree that the glosses are probably in 14th-century script, but I don’t agree that it’s illegible (except in places where the ink has worn off). It is somewhat messy, but mostly readable.
The red text is not ciphertext and I don’t think what resembles a cipher list at the end is necessarily related to the red text in the margins.
The Text in Red Ink
So what are the marks in red? They’re citations, cross-references. They follow a fairly regular format. Here’s an example, and below the screensnap I’ll give a breakdown of the parts:

The first symbol in each line is a paragraph-reference marker. These symbols are found in a variety of languages that use the Latin character-set.
Paragraph markers are recognizable because many are constructed using a loop or semi-circle or two, plus a line or two. If the line passes through a semi-circle, it looks a bit like a pitchfork. Sometimes a plus-symbol or hook-shape will be added.
This combination of shapes makes them sufficiently different from Latin letters that they can be added to the manuscript in the same color ink as the main text, and still be spotted without too much trouble. They mark passages-of-interest pointing to specific notes in the margins.
Here is an example from another manuscript. To modern eyes, the reference symbol in the bottom-left might look like a Venus symbol, but that is a coincidence. It looks like this because it dips into the same storehouse of components as the paragraph markers above—in this case, a loop and plus-symbol:

Here is a simpler version from an earlier folio in the same manuscript:

Sometimes the reference symbols are more complex. This often happens if there are many notes and uniqueness is desired. Some writers recycled the same markers on the next folio, others added new ones until they reached the end of a section.
The example below is composed of a semi-circle, line, and hook-shape. You can see the symbol next to the marginal note and in the passage it references in the main text to the right:

The Tranchedino collection of diplomatic ciphers includes many of these paragraph markers as cipher symbols. Since they are numerous, they are a convenient source for glyph-shapes. Often they have been combined with regular Latin letters.
But the U of F manuscript is not ciphertext. It’s Latin. So let’s look at the rest of the line of cryptic text.
- After the paragraph-reference symbol, the two top lines are followed by a number in Roman numerals. In this example, we see the numbers 24 and 22 (or possibly 20 • 2 since there is a dot in between).
- Next there is a q. or, as in the third line, a series of short abbreviations. Single- and double-letter abbreviations are very common in Latin for words and phrases like a.d. (anno domini) i.e. (id est) q (qui/quo), n.b. (nota bene), and many more.
- After the q. abbreviation in the first two examples is another Roman numeral.
- All three are followed at the end by a word or two, abbreviated.
I recognized the number-q-number pattern as a formal reference convention, so I looked for an example of the same style in a printed book. I felt it might be an easier way to demonstrate that this is not “mysterious” text but quite an orderly way of doing things.
I found this canon reference arranged according to the same pattern as the notes in red ink. It is comprised of a Roman numeral, q. abbreviation, Roman numeral and short summary text:
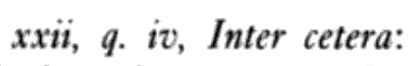
The q. can mean many things in Latin (q-words are very common), but in this context, it refers to quaestio (question).
So the printed phrase reflects the format of the first two lines of the text in red ink.
The third line is different from lines 1 and 2. Instead of a Roman numeral followed by q., it has de p d, which is usually the Latin abbreviation for de poenitentia, distinctio, followed by the number 1 and a note.
The Terse Abbreviations at the Ends of Lines
In the U of F manuscript, the summary text at the end of each line is abbreviated. While scanning through it, I saw abbreviations for Paulus, penitence, loses (verb, loses his life), from good (ex bono), don’t (noli), decree (fiat), leader (ducator), and holy (et sancta), and Ecclesiastes (bible reference). There were also references to “three” (trinity?), six days (creation?).
Here is another example from page 3 that follows the same format, consisting of paragraph-marker, Roman numeral q[uaestio], Roman numeral and abbreviated note. Sometimes there is an additional numeral and note. If the paragraph marker is omitted, it probably refers to the same section in the main text as the citation above it.
At the end of the line that starts with the number 24 is the abbreviation for “sanctus” preceded by the letter “d”. In many cases, “d” stands for deus, but in this case, it is dominus to represent the Latin phrase dominus sanctus (Holy/Sacred Lord):

On the line below it, are Roman numerals and a common abbreviation for variations of ecclesia/ecclesiastis/ecclesiastes/ecclesiastem. At the end is the abbreviation for ad fidem (to faith).
This is a copy of the New Testament, so the notes are completely consistent with the subject matter of the main text.
The abbreviations are terse, you have to know Latin to recognize them, but I can’t see any “mystery” or intention to hide. It is a standard citation system, and medieval scribes were familiar with terse abbreviations.
Now, let’s look at the cipher-like chart on the second-to-last page…
Is There a Cipher Alphabet?
There is an alphabet paired with a set of numbers near the end of the manuscript. It looks like this (I have broken it into two parts so it will fit better on the screen, but you can see the original scan here on page 162):

It’s very tempting to think that 1) this is a substitution cipher and 2) the numbers might be related to the many numbers in red ink in the main manuscript, but I am doubtful.
First, this is a very limited set of numbers (only 16) and the red glosses don’t have limits on what numbers can be used, as long as they are relevant to the citation.
Secondly, these are Indic-Arabic numbers. They were rarely used until later in the 14th century. They do exist earlier in some of the scientific manuscripts (mathematicians and astronomers recognized their utility) but this is a biblical text and it would be unusual to see them in this context in the 12th or 13th centuries. In other words, this alphabet may have been added after the red notes and probably a century or so after the original script.
Even if the red notes and the cipher-like alphabet were added at the same time (which is possible, since the writing style is the same), they don’t appear to serve the same purpose.
So, let’s say for a moment that the alphabet was added because there was space, not because it was connected to the red citations.
Assuming the alphabet stands on its own, can we determine if it is a cipher key?
Numeric ciphers were not common, but they did exist, and alphabetic cipher keys are sprinkled among medieval manuscripts, but one has to wonder… why were these particular letters and numbers chosen? The numbers are in sequence in the sense of getting larger and, depending on the language, the alphabet is incomplete.
What Comprises an Alphabet?
Languages have different sounds, which results in different alphabets, so a “full” alphabet depended on the language.
In Latin manuscripts, the alphabet usually consisted of
a, b, c, d, e, f, g, h, i, l, m, n, o, p, q, r, s, t, u/v, x, z
Some scribes substituted a “y” shape for “i”. The letter “k” was usually only included if there were loanwords. The lettershapes “u” and “v” were roughly analogous. The letter “j” didn’t exist as we know it. What looks like a “j” in medieval manuscripts was actually a capital “i” (for names) or an embellished “i”. We know this because complete alphabets were often added in margins and they generally did not include “j”. The letter “y” was often absent. Sometimes the letter “i” and a final-i (“i” with a descending tail) were written together to resemble ÿ, but but most of the time, this was “ii”, not “y”.
If the language was German, “k” and sometimes “w” were included. In Middle English, most letters were included, except for “j”, but some scribes used “y” instead of “i”. Old English had letters (like thorn and wynn) that are not used in modern English and were uncommon in continental manuscripts outside of Saxony.
The Organization of Numbers in the Alphabet Chart
The U of F manuscript includes the following letters (with the “r” having been squeezed in and apparently associated with the “p”, similar to the way the “u/v” was associated with the “z”). Next to each is a number and some of the numbers encompass two letters.
If this were a cipher key, it would not be unusual for one cipher glyph to represent two letters, but it’s not certain that it’s a cipher key:
a, b, c, d, e, f, g, h, i, l, m, n, o, p, r, s, t, u/v (tilted back), z
This is similar to the Latin alphabet, since j and k are not included, but there is a rather significant omission. The letter “q” was very common in Latin texts. It would be difficult to write Latin without a “q”, especially considering many abbreviated “q” words were abbreviated to only the “q”, omitting the rest of the letters.
So, if it’s an alphabet what language is it?
Sixteen numbers is not enough characters to represent most alphabets (most of them had around 21 characters or more) unless there were many-to-one assignments. Unfortunately, the more letters that are compressed down to one cipher glyph, the harder it is to decrypt a message (even for the person who composed the message). And there’s a limit—at some point, it becomes a one-way cipher.
Why so few characters? Even the old Italic alphabet needed 17 characters.
And why the sequential order of numbers? Eight of the numbers are in sequences of four (which makes it much easier to crack a cipher) and all of them are in numerical sequence, even if there are gaps. If this were a cipher, it would be considered a “light” version, minimally secure.
A comment on the alphabet from the University of Florida article:
Is it the key to a secret code? No one knows. You can try to decipher it… (U of F News, 2018)
I love puzzles and I enjoy collecting medieval ciphers. I wanted this to be a cipher key, but I strongly suspect that it’s not.
What else could it be? It’s not likely to be a tally sheet, as the order of the letters follows the order of the numbers, and it doesn’t appear to be numbers related to playing cards (which were popular at the time), or other sorts of games.
Another Explanation
I had to think about this for a few minutes to come up with a way to explain the sequence of numbers (from small to large) and the fact that many of the numbers are adjacent (26, 27, 28, 29). These characteristics are not common in cipher keys.

I think this might be a short index, or table of contents, with the numbers referencing something alphabetical.
If so, then it could be interpreted this way… the “a” entries begin on page 1, the p and r entries begin on page 28, and the u/v and z entries on page 34.
The largest gap is between “a” and “b” and this would fit with many kinds of lists, in which the “a” entries are more numerous than those beginning with other letters. Following this logic, the next most numerous section begins with “s”, followed by “c” and “i”. Using letter-frequency charts, it might be possible to figure out the potential language if this were an index to a dictionary, but this could be an index to something else, in which case, the frequencies might not divulge anything that specific.
The alphabet chart doesn’t appear to relate to the six pages in brown ink that precede them. Maybe it references something external to this manuscript (or something that is no longer bound inside it).
I thought the lack of a “q” might indicate a medieval German alphabet, but the “k” is also missing and “k” was common in German.
Summary
Even though I wanted this to be a cipher, it is clear that the notes in red ink are Latin cross-references in canon-citation style. The abbreviations are terse, you have to know Latin to expand them, but I didn’t see anything unusual about the words or the way they were formatted.
The alphabet at the end was more intriguing, but after some consideration, it is probably not a cipher either. The numbers are organized in a way that is uncommon for ciphers but logically consistent with something organized with gradually increasing numbers.
It might be some kind of index. If so, the numbers are probably page numbers. Why might there be letters missing? If it’s an index to a specialized list (like the names of towns, or the names of noble families), then some letters might not be used. Maybe there’s a document somewhere that is about 34 to 40 pages long whose content matches the number sequence and maybe not.
I’m still keeping my eyes open for medieval ciphers. This was less of a mystery than I expected, but there will be others.
J.K. Petersen
© Copyright 9 April 2020, J.K. Petersen, All Rights Reserved