
http://modernsmile.com/2010/10 I’ve been trying to find a way to introduce the concept of entropy without loading it full of mathematical formulas. The word “entropy” is often invoked when comparing the quantity, frequency, and position of the VMS glyphs, which is easier to describe in numbers than in words. After some consideration, I decided that at least some aspects of text analysis could be described with charts and examples rather than with numbers.
Imagine an ice cube—frozen water. The molecules are linked in a tighter, more ordered structure. When heat is applied, the structure changes, becomes looser, and exhibits higher entropy.

This illustration is over-simplified but can still give an idea of how water molecules are more tightly ordered as ice and more loosely associated and disordered, as steam, thus illustrating states of lower and higher entropy. Similar relationships can be found in text. The association of the VMS glyphs to one another, and their relative quantity and frequency within this arrangement, can be studied and compared to ciphered texts and natural languages and expressed as numerical values.
If you’ve read my previous blogs, you’ve probably noticed I talk about the “structure” of the VMS text being different from natural languages. I gave a nutshell version of it in the blog about creating text that looks more like Voynich text where I described some of the ordering and relationships that are characteristic of the selected sample. I did not write out rules for the entire manuscript because that would take 20 blogs, but the concept can be applied to the text as a whole once it is understood that the glyphs tend to be ordered in a specific way.
So how does the idea of entropy apply to text? Maybe this too, is easier to explain with a diagram.
- On the left is an alphabet. By definition, an alphabet contains a specific character set, commonly consisting of consonants and vowels (although not every language has vowels), usually in a specific order decided by convention. In terms of text, an alphabet is relatively low entropy.
- In the middle are words consisting of nouns, verbs, and a couple of adjectives. Even though it uses the same characters as the alphabet on the left, the characters have greater variance in where they are in relation to other letters and may be used more than once. The letters exhibit higher entropy than the alphabet.
- On the right is alphabet soup. The letters don’t have to follow any particular order, direction, or spatial relationship to other letters. Alphabet soup has high entropy compared to words, it’s somewhat chaotic (but that’s okay, it tastes good).
Entropy and the VMS
 n the Voynich world, there is an oft-quoted statistic that the text exhibits low entropy compared to natural languages. It has been said that only one or two languages come close (with Hawaiian being one of them).
n the Voynich world, there is an oft-quoted statistic that the text exhibits low entropy compared to natural languages. It has been said that only one or two languages come close (with Hawaiian being one of them).
This comes as no surprise if one looks closely at the Voynich text. I created my own transcription of the entire manuscript several years ago, so I had no choice but to examine and evaluate every letter, every space, and one can’t help noticing how certain combinations repeat, and how certain letters re-occur in the same positions with surprising frequency. Line structure follows patterns also, with specific glyphs falling at the beginnings or ends of lines more often than one might expect.
How does the entropy of Voynich text compare to other 15th-century manuscripts? This is a broad and complex question, far beyond the scope of a blog whose purpose is to introduce the idea without all the math, but it probably wouldn’t hurt to show one example (note that entropy and repetition are related but not identical concepts—I’ll deal with repetition more specifically in a separate blog).
Comparing Two Snippets
Here’s an example from folio 81r I chose because the page layout reminds me of a song or poem and it’s not too hard to find 15th-century poetry for comparison. Poetry tends to be more repetitious and regimented than regular text, so I thought a medieval poem might resemble VMS text more than regular narrative text.
Excluding the fragments beginning with “o” on the right, and assuming the “9” and the “o” on the left are single characters, there are 23 word-tokens, and 20 repeated sequences of three characters (I was bleary-eyed from lack of sleep when I first wrote this, so I corrected this paragraph Nov. 10th).

Note that the repeating 3-glyph sequences are always in the same positions at the beginnings or ends of word-tokens. This is not a pattern we typically associate with natural languages except in specific forms of text such as prayers. poetry, or lists.
Compare this to a 22-word snippet from a 15th-century cosmology-themed rhyming poem in Italian that includes 6 repeated sequences:

In this example, there are also three 3-character sequences, but each one repeats only twice. Since this is a rhyming poem, two sequences are at the ends of words (and lines) but, unlike the VMS, the “chi” sequence appears in the middle of one word and at the beginning of another—it’s not positionally constrained.
Here’s another example, from one of the large-plant pages:
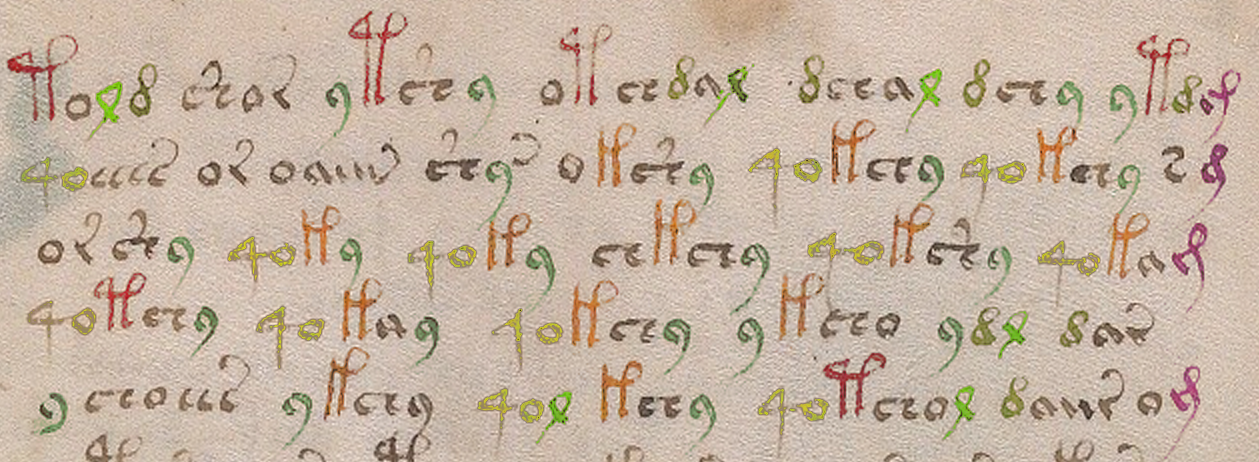
I colorized the sample to make it easier to see the patterns. Note that for the purposes of this example, I made the assumption that the “4o” sequence is intended to be together (this appears to be the case in most of the manuscript, but there are exceptions where the “4” appears without the “o”).
Even though the formatting and apparent subject matter of this plant page is quite different from the previous example, there are clearly many similarities, such as a high percentage of repeating sequences: the “4o” combination is almost always followed by a gallows character, the “c” and “r” shapes with tails are at the ends of words, the “9” is usually at the ends of words and frequently follows EVA-ch or EVA-sh, and the Latin “-ris, -cis” abbreviation (EVA-j) is always at the ends of lines (in other parts of the manuscript “j” appears elsewhere, but not as frequently as at the ends of lines). As I’ve mentioned on previous blogs, the structure is quite rigid.
Entropy is measured in a number of ways—it is not limited to repeating glyph sequences. Measures of word-length, character variability, and individual character combinations are all taken into consideration. Notice that the position of characters in relation to each other is more variable in the Italian example and the character set is larger. Most of the VMS text is expressed with about 17 to 20 of the more common glyph-shapes. The old Italic alphabet had only 17 characters, so it’s not an unworkable number but it’s fewer than most alphabets of the time and significantly less if you consider the various diacritical marks and abbreviation symbols that were in regular use. It’s also significantly less if any of the VMS glyphs are markers, nulls, or modifiers.
how to get Aurogra online no prescription in 1 days Summary
These snippets are only examples—they don’t mean anything by themselves. Genuine research requires hundreds or sometimes hundreds-of-thousands of samples and many different kinds of comparisons. For a draft tutorial on entropy as it applies to the Voynich manuscript, you can read Anton’s post on the Voynich forum. For mathematical studies of entropy, you can consult scientific journals and blogs, and books such as CryptoSchool by Joachim von zur Gathen. For a basic introduction, however, you can look through the VMS and see that the above patterns are common to the text as a whole—glyph-groups tend to repeat, and the same glyph-groups end up in the same positions much of the time, with variation in letter-position being very constrained, all of which tend to lower the entropy.
Does this argue against the VMS being natural language?
Maybe.
But that’s a subject for another blog.
J.K. Petersen
© Copyright 2016 J.K. Petersen, All Rights Reserved