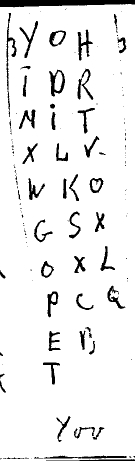The Strange Story of Leonell Strong

Antiquarian Wilfrid Voynich rediscovered the VMS in a cache of old books in Italy but never solved the mystery of the text.
In 1945, Leonell Strong claimed to have solved the mysterious text of the Voynich Manuscript. He was not the first to attempt to decipher it after antiquarian Wilfrid Voynich acquired it and brought it to America as the Great War broke out in Europe.
In his lifetime, Wilfrid Voynich, a book dealer, corresponded with many people in an effort to decode the VMS and solidify its provenance. If it could be connected with important historical figures, the value would increase and Voynich, a businessman, would profit from his investment.
Voynich died in 1930, no wiser about the contents of the manuscript than when he began. After his death, his wife, Ethel Voynich, continued to try to unlock its secrets, to no avail. William Friedman, an eminent cryptologist, initiated a study group to decipher it in 1944 but, with the war looming large (and perhaps because of lack of progress), the study group was disbanded, in 1946.
You can read an extensive history and ongoing research at voynich.nu.
The manuscript was eventually sold to Hans P. Kraus, who also failed to decode it or sell it at his asking price of $160,000. Kraus eventually donated it to the Beinecke Library, in 1969, where it remains to this day. Before this happened however, Leonell Strong, cancer scientist and amateur cryptographer, came into the picture around the same time Friedman’s study group was trying to decode the manuscript.
The Strong Approach
 Leonell Strong claimed to have decrypted the text based on analyzing photostats of two of the VMS folios, which he refers to as Folio 78 and Folio 93. There had already been articles about the manuscript published by John M. Manly and Hugh O’Neill in Speculum, in 1921 and 1944, so he was not starting from a blank slate. Based on its format and illustrations, it was already assumed by the 1940s that it might be an herbal and medical text with a particular emphasis on women’s health.
Leonell Strong claimed to have decrypted the text based on analyzing photostats of two of the VMS folios, which he refers to as Folio 78 and Folio 93. There had already been articles about the manuscript published by John M. Manly and Hugh O’Neill in Speculum, in 1921 and 1944, so he was not starting from a blank slate. Based on its format and illustrations, it was already assumed by the 1940s that it might be an herbal and medical text with a particular emphasis on women’s health.
Strong was eager to publish the medical-related information he felt he had uncovered, but he didn’t explain his solution because he wanted to decode more of the pages and was earnestly trying to acquire more photostats.
Strong claimed the reason he didn’t want to reveal his decryption method was because of “present war conditions”. My guess is that he felt the information in the manuscript, if any of it provided unique insights into medieval remedies, would constitute a treasure trove of publishable articles and if he was the first to decipher it, he could benefit from writing up his discoveries. If he revealed his decryption scheme too soon, others might get the data first.
Despite considerable efforts—that were apparently rebuffed—he never received any additional pages. It has been said that Strong died without revealing his methods, but there are notes to his thought process and if you follow those notes you can puzzle out what he did and where he went wrong and why we are still trying to decode the VMS.
Publications
 Strong described some of his findings in an article in Science (June 1945), in which he summarizes the background of the manuscript, including the assumption, by O’Neill (1944) that the manuscript must post-date the journeys of Columbus because the VMS includes New World plants (a theme revived in January 2014 by Tucker and Talbot in HerbalGram).
Strong described some of his findings in an article in Science (June 1945), in which he summarizes the background of the manuscript, including the assumption, by O’Neill (1944) that the manuscript must post-date the journeys of Columbus because the VMS includes New World plants (a theme revived in January 2014 by Tucker and Talbot in HerbalGram).
Strong claimed that the VMS was based on “… a double system of arithmetical progressions of a multiple alphabet…” and that the VMS author was familiar with ciphers discussed by Trithemius, Porta, and Selenius as well as one of Leonardo da Vinci’s documents. These historic treatises date from the late 1400s to the 1600s, long after the VMS is thought to have been penned.
 Strong also claimed that certain of the “peculiar” glyphs in the VMS are mirror images of Italian letters but doesn’t explain exactly which VMS letters he means.
Strong also claimed that certain of the “peculiar” glyphs in the VMS are mirror images of Italian letters but doesn’t explain exactly which VMS letters he means.
Given that Strong wasn’t very good at reproducing the VMS characters himself (the slants, connections, and pen sequence are mostly wrong), his analysis of what inspired the shapes is questionable—VMS shapes are found in many alphabets, including those around the Mediterranean and those in ancient documents recording dead languages.
Strong made further assumptions about what constitutes the VMS “alphabet”. In his chart, he excluded “j” and “z” and included both “u” and “v”. This works for some languages, but not for others. Clearly his assumptions were already influencing his choice of how the information was encoded, before he had barely begun, and his charts further indicate that he never looked beyond a substitution code, even if approached in a reverse numeric fashion.
Anthony Askham—the VMS Author
Many have criticized Strong’s decryption scheme based on his contention that the author of the VMS is Anthony Askham, an English academic active in the mid-1500s. I think the more important question is whether Strong’s decryption process was viable and accurate. Conjecture about who wrote it can come later and the decryption itself shouldn’t be discounted because the hypothesis about who wrote it may be wrong.
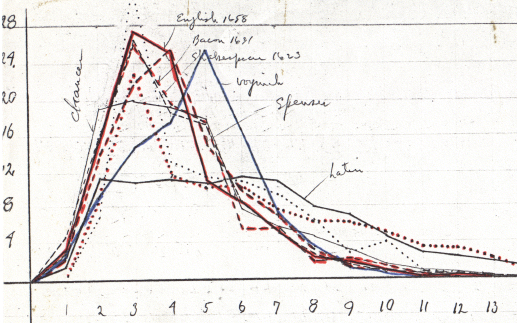
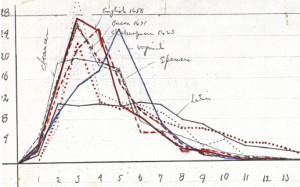 I won’t go through Strong’s entire process here, it’s too long for one article (and there’s no point in detailing a method that doesn’t work), but he created a series of frequency analyses of characters and mapped them to similar analyses of a few European languages and, after assuming which one most closely matched the VMS, he created charts trying to relate various Latin characters to VMS characters for that language, dating each attempt over a series of weeks.
I won’t go through Strong’s entire process here, it’s too long for one article (and there’s no point in detailing a method that doesn’t work), but he created a series of frequency analyses of characters and mapped them to similar analyses of a few European languages and, after assuming which one most closely matched the VMS, he created charts trying to relate various Latin characters to VMS characters for that language, dating each attempt over a series of weeks.
Where Strong Becomes Weak
And now we get to the important part and the reason Strong’s method, already based on a series of possibly incorrect assumptions, doesn’t work. But first, what were the results of his decryption? Here’s a sample of the decrypted text which he describes as medieval English:
WIT SEEK TO EDIT NOT IDLE/IDEL? FOKLUORE FIT ES ME I MEATH TRUNNG IQUERI SELFLI O’ER IT NICLY RUTEN GLAVE QUIR ONGI SEM TE BELI’D
Apparently, Strong was told in no uncertain terms that this was not medieval English and made some later efforts to map the text to Gaelic, apparently without success (or maybe he just gave up).
So why is the text above not medieval English?
To list a few more obvious examples..
- They don’t have the word “seek” in Old English. In the sense of searching for something, they say áséc or sēċan or, if you’re seeking out something, you can say gitan or begeten. In old Norse and Dutch it’s søk/soek and German, suchan. In Middle English, sēċan became seken.
- Meath isn’t a word, nor is trunng, although -rung was a common suffix in Old English (e.g., clatrung describes a clattering sound).
- Iqueri isn’t a word in medieval English. It looks more like Latin and while Latin was often mixed in with Old English, it was not usually done in this way and doesn’t mean anything unless you break it into two words.
- Selfli isn’t a word, although self– can be used as a prefix (as in selflicne which can mean self-centered or self-satisfied). If the words around it made sense, you could argue that selfli was an abbreviation for selflicne, but the context doesn’t appear to support this interpretation.
Taken together, there are too many words that aren’t really words, they just look familiar (I’ll explain why below), and the grammar doesn’t pan out either. Even if you evaluate it as “note form” writing, it doesn’t appear to have coherent meaning.
Let’s take another passage, quoted by Strong in his article submission, that seems more credible:
HSAWE-TRE APLE ETTEN VNLICH ARUMS CAN DRAVE WICKS AIR FROM SPLEEN: LIKE SISLE HE DRIS GAS AUT OVARI.
This seems as though it might be real medical information, about eating apples and using arum (which Strong interprets as alum without explaining why it might be alum rather than arum lily) and driving air from one’s spleen as well as driving gas from the ovary.
To understand why this isn’t any more credible than the previous quotation, you have to look at how Strong arrived at these words. Did he really decrypt the letters or did he look at many possible combinations of letters and simply guess, for each individual word, what it might be?
The Madness in the Method
How did Strong arrive at these tokens that look so much like real words?
 Once he had a system worked out for mapping the VMS letters to Latin letters, he began evaluating each VMS word-token on its own against a list of “alphabets” he had developed for decipherment. In other words, he had several rows of letters (based on letter frequencies) that each VMS letter might represent. Note the column numbers on the far left. He was saying that A could be any of several VMS glyphs, B could be any of several glyphs, etc., on through the alphabet.
Once he had a system worked out for mapping the VMS letters to Latin letters, he began evaluating each VMS word-token on its own against a list of “alphabets” he had developed for decipherment. In other words, he had several rows of letters (based on letter frequencies) that each VMS letter might represent. Note the column numbers on the far left. He was saying that A could be any of several VMS glyphs, B could be any of several glyphs, etc., on through the alphabet.
Even if you ignore all of his previous assumptions about language and which glyphs constitute the “alphabet”, and his assumptions about character frequency (based on already deciding on the underlying language), even if all those assumptions were correct, here’s where Strong over-reaches in his eagerness to find meaning in the VMS characters.
Strong created a set of index cards with the possible letter correspondences to each VMS glyph. You can see three of the word-tokens recorded in this example in terms of possible letters from the chart mentioned above.
The first has eight different possible interpretations of the six glyphs in the word token, the second has eight interpretations for five glyphs and the third he wasn’t so sure of (it may comprise less common glyphs) and thus he only proposed five for the five glyphs in the third example.

Under each one is the decrypted word. Strong has written ciphre, swais and lunar. How did he arrive at these? From what I can see, he took a letter from each column and combined them with the others until it became something that looked like a word.
He doesn’t appear to be following a mathematical model even though he described it as a mathematical cipher. In fact, examining all the available index cards, it looks like he inserted letters when he couldn’t create a word in a linear fashion. I have no proof of this, but based on the words noted on 13 index cards, it strongly appears as though his word formation process was subjective. There’s no sign of him uncovering a key, as would be needed for the Porta cypher, or of him necessarily having the alphabetic sequence correct, an important aid in deciphering double ciphers with this structure.
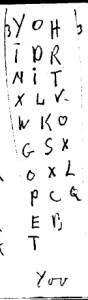 If Strong could come up with a word by using a letter from each column, he did so. If he couldn’t get all of them to work together, he made something up to fill in the gaps. The words themselves surely came from his own vocabulary, since other word combinations are possible but he didn’t list them. For example, a token he interpreted as “childe” (which works for the first three columns but not the remaining two) could also be deciphered as POLLIS, DOGFAR, COWHAG, PURPLO, SOWGAS, LOGLAD, LOWGAS, FORLAG, OWLPAR, or several others, using only the letters listed and not adding anything that isn’t (and that’s only if you look for English-sounding tokens).
If Strong could come up with a word by using a letter from each column, he did so. If he couldn’t get all of them to work together, he made something up to fill in the gaps. The words themselves surely came from his own vocabulary, since other word combinations are possible but he didn’t list them. For example, a token he interpreted as “childe” (which works for the first three columns but not the remaining two) could also be deciphered as POLLIS, DOGFAR, COWHAG, PURPLO, SOWGAS, LOGLAD, LOWGAS, FORLAG, OWLPAR, or several others, using only the letters listed and not adding anything that isn’t (and that’s only if you look for English-sounding tokens).
The next one, interpreted as YOV (YOU?), can just as easily be read as YOR, TOR, POT, GOT, GLO, PIT, TIT, GOO, POO, or POX using his system, so he’s not only subjectively creating the words, he’s subjectively choosing which, out of many possible words, might fit with the words that precede or follow it and then fitting those into his assumption that the text was about plants and medicine.
It’s easy to assume from the drawings that the text is about medical folklore, and that might be the simplest explanation, but we don’t know for certain if the person who created the drawings also added the text. There are herbals from that period that contain only images, the text was never added, so it’s possible the text was added to the VMS by someone else and is sensitive political commentary or historical, rather than relating to plants. Maybe an unfinished herbal compendium was taken into enemy territory as a ruse (the way a botanist was included in one of the European spying expeditions to the Ottoman palace). Perhaps spy observations were added around the drawings.
Summary
Strong assumed English was the underlying language of the VMS based on creating frequency charts for only a few languages and on the assumption that each VMS glyph represented one character. From that very significant assumption, he tried to create English-sounding words by juggling his letter frequency charts and their derived possible alphabets.
 Unfortunately, even with a subjective infusion of natural-sounding syllables, most of the decrypted text is nonsense and none of it fits any known version of medieval English from the 14th to 17th centuries.
Unfortunately, even with a subjective infusion of natural-sounding syllables, most of the decrypted text is nonsense and none of it fits any known version of medieval English from the 14th to 17th centuries.
Strong will be remembered for his contributions to oncology and the study of genetics in mice, but his status as a cryptographer will have to remain in the amateur category—a hobby, which means we still have a mystery to solve.
J.K. Petersen
© Copyright 2016 J.K. Petersen, All Rights Reserved